2025-06-13 06:03:17 +00:00
import { PrismaClient , Prisma } from "@/generated/client" ;
2026-05-19 08:49:18 +00:00
import bcrypt from "bcryptjs" ;
2025-03-09 09:45:13 +00:00
const prisma = new PrismaClient ( ) ;
2025-06-13 06:03:17 +00:00
const dockerConfigData : Prisma.DockerConfigCreateInput [ ] = [
2025-03-16 11:43:21 +00:00
{
2025-06-13 06:03:17 +00:00
language : "c" ,
image : "gcc" ,
tag : "latest" ,
2026-05-13 07:10:06 +00:00
workingDir : "/workspace" ,
2025-06-13 06:03:17 +00:00
compileOutputLimit : 1 * 1024 * 1024 ,
runOutputLimit : 1 * 1024 * 1024 ,
2025-03-16 11:43:21 +00:00
} ,
{
2025-06-13 06:03:17 +00:00
language : "cpp" ,
image : "gcc" ,
tag : "latest" ,
2026-05-13 07:10:06 +00:00
workingDir : "/workspace" ,
2025-06-13 06:03:17 +00:00
compileOutputLimit : 1 * 1024 * 1024 ,
runOutputLimit : 1 * 1024 * 1024 ,
2025-03-16 11:43:21 +00:00
} ,
] ;
2025-06-13 06:03:17 +00:00
const languageServerConfigData : Prisma.LanguageServerConfigCreateInput [ ] = [
2025-03-09 09:45:13 +00:00
{
2025-06-13 06:03:17 +00:00
language : "c" ,
2026-05-19 08:49:18 +00:00
protocol : "ws" ,
hostname : "localhost" ,
port : 4594 ,
2025-06-13 06:03:17 +00:00
path : "/clangd" ,
} ,
{
language : "cpp" ,
2026-05-19 08:49:18 +00:00
protocol : "ws" ,
hostname : "localhost" ,
port : 4595 ,
2025-06-13 06:03:17 +00:00
path : "/clangd" ,
} ,
] ;
const problemData : Prisma.ProblemCreateInput [ ] = [
{
displayId : 1000 ,
difficulty : "EASY" ,
isPublished : true ,
2025-06-16 08:59:48 +00:00
isTrim : true ,
2025-06-13 06:03:17 +00:00
localizations : {
2025-03-09 09:45:13 +00:00
create : [
{
2025-06-13 06:03:17 +00:00
locale : "en" ,
type : "TITLE" ,
content : "Two Sum" ,
} ,
{
locale : "zh" ,
type : "TITLE" ,
content : "两数之和" ,
} ,
{
locale : "en" ,
type : "DESCRIPTION" ,
content : ` Given an array of integers \` nums \` and an integer \` target \` , return indices of the two numbers such that they add up to \` target \` .
2025-03-09 09:45:13 +00:00
You may assume that each input would have * * exactly one solution * * , and you may not use the same element twice .
You can return the answer in any order .
# # Examples
# # # Example 1
\ ` \` \` shell
Input : nums = [ 2 , 7 , 11 , 15 ] , target = 9
Output : [ 0 , 1 ]
Explanation : Because nums [ 0 ] + nums [ 1 ] == 9 , we return [ 0 , 1 ] .
\ ` \` \`
# # # Example 2
\ ` \` \` shell
Input : nums = [ 3 , 2 , 4 ] , target = 6
Output : [ 1 , 2 ]
\ ` \` \`
# # # Example 3
\ ` \` \` shell
Input : nums = [ 3 , 3 ] , target = 6
Output : [ 0 , 1 ]
\ ` \` \`
# # Constraints
\ ` \` \` math
2 <= nums . length <= 10 ^ 4
\ ` \` \`
\ ` \` \` math
- 10 ^ 9 <= nums [ i ] <= 10 ^ 9
\ ` \` \`
\ ` \` \` math
- 10 ^ 9 <= target <= 10 ^ 9
\ ` \` \`
< div align = "center" >
Only one valid answer exists .
< / div >
2025-03-27 06:10:03 +00:00
* * Follow - up : * * Can you come up with an algorithm that is less than $O ( n ^ 2 ) $ time complexity ?
2025-03-09 09:45:13 +00:00
-- -
2025-03-27 06:10:03 +00:00
< Accordion title = "Hint 1" >
A really brute force way would be to search for all possible pairs of numbers but that would be too slow . Again , it ' s best to try out brute force solutions for just for completeness . It is from these brute force solutions that you can come up with optimizations .
< / Accordion >
< Accordion title = "Hint 2" >
So , if we fix one of the numbers , say \ ` x \` , we have to scan the entire array to find the next number \` y \` which is \` value - x \` where value is the input parameter. Can we change our array somehow so that this search becomes faster?
< / Accordion >
< Accordion title = "Hint 3" >
The second train of thought is , without changing the array , can we use additional space somehow ? Like maybe a hash map to speed up the search ?
< / Accordion > ` ,
2025-06-13 06:03:17 +00:00
} ,
{
locale : "zh" ,
type : "DESCRIPTION" ,
content : ` 给定一个整数数组 \` nums \` 一个整数 \` target \` , 返回数组中两个数的下标,使得它们的和等于 \` target \` .
你 可 以 假 设 每 个 输 入 恰 好 有 一 个 解 , 并 且 你 不 能 重 复 使 用 同 一 个 元 素 。
答 案 可 以 按 任 意 顺 序 返 回 。
# # 示 例
# # # 示 例 1
\ ` \` \` shell
输入 : nums = [ 2 , 7 , 11 , 15 ] , target = 9
输 出 : [ 0 , 1 ]
解释 : Because nums [ 0 ] + nums [ 1 ] == 9 , we return [ 0 , 1 ] .
\ ` \` \`
# # # 示 例 2
\ ` \` \` shell
输入 : nums = [ 3 , 2 , 4 ] , target = 6
输 出 : [ 1 , 2 ]
\ ` \` \`
# # # 示 例 3
\ ` \` \` shell
输入 : nums = [ 3 , 3 ] , target = 6
输 出 : [ 0 , 1 ]
\ ` \` \`
# # 约 束
\ ` \` \` math
2 <= nums . length <= 10 ^ 4
\ ` \` \`
\ ` \` \` math
- 10 ^ 9 <= nums [ i ] <= 10 ^ 9
\ ` \` \`
\ ` \` \` math
- 10 ^ 9 <= target <= 10 ^ 9
\ ` \` \`
< div align = "center" >
只 存 在 一 个 有 效 的 答 案 。
< / div >
* * 进 阶 问 题 : * * 你 能 否 设 计 一 个 时 间 复 杂 度 低 于 $O ( n ^ 2 ) $ 的 算 法 来 解 决 这 个 问 题 ? ?
-- -
< Accordion title = "提示 1" >
一 种 真 正 的 暴 力 方 法 是 遍 历 所 有 可 能 的 数 字 对 , 但 这 种 方 法 太 慢 了 。 不 过 , 为 了 完 整 性 , 尝 试 暴 力 解 法 仍 然 是 有 意 义 的 。 正 是 从 这 些 暴 力 解 法 中 , 你 才 能 找 到 优 化 的 思 路 。
< / Accordion >
< Accordion title = "提示 2" >
所 以 , 如 果 我 们 固 定 其 中 一 个 数 字 , 例 如 \ ` x \` , 我们就必须遍历整个数组来找到另一个数字 \` y \` ,而 \` y \` 等于 \` value - x \` (这里的 value 是输入的参数)。我们能否以某种方式对数组进行处理,从而让这种查找变得更快呢?
< / Accordion >
< Accordion title = "提示 3" >
第 二 种 思 路 是 , 在 不 改 变 数 组 的 前 提 下 , 我 们 能 否 借 助 额 外 的 空 间 呢 ? 比 如 , 是 否 可 以 用 哈 希 表 来 加 快 查 找 速 度 ?
< / Accordion > ` ,
} ,
{
locale : "en" ,
type : "SOLUTION" ,
content : ` 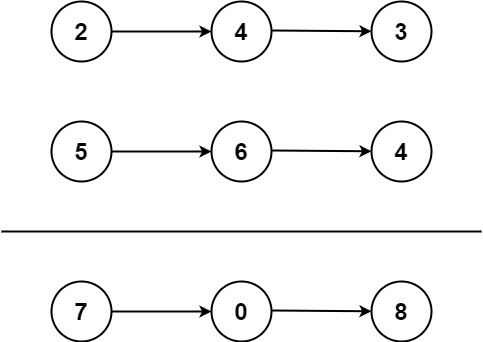
2025-03-27 06:10:03 +00:00
# # Approach 1 : Brute Force
2025-03-10 14:40:37 +00:00
# # # Algorithm
The brute force approach is simple . Loop through each element $x $ and find if there is another value that equals to $target - x $ .
# # # Implementation
2025-06-13 06:03:17 +00:00
\ ` \` \` c showLineNumbers {2-3,6-7,15}
2025-03-10 14:40:37 +00:00
int * twoSum ( int * nums , int numsSize , int target , int * returnSize ) {
for ( int i = 0 ; i < numsSize ; i ++ ) {
for ( int j = i + 1 ; j < numsSize ; j ++ ) {
if ( nums [ j ] == target - nums [ i ] ) {
int * result = malloc ( sizeof ( int ) * 2 ) ;
result [ 0 ] = i ;
result [ 1 ] = j ;
* returnSize = 2 ;
return result ;
}
}
}
// Return an empty array if no solution is found
* returnSize = 0 ;
return malloc ( sizeof ( int ) * 0 ) ;
}
\ ` \` \`
# # # Complexity Analysis
- * * Time complexity : * * $O ( n ^ 2 ) $ .
For each element , we try to find its complement by looping through the rest of the array which takes $O ( n ) $ time . Therefore , the time complexity is $O ( n ^ 2 ) $ .
- * * Space complexity : * * $O ( 1 ) $ .
The space required does not depend on the size of the input array , so only constant space is used .
2025-06-13 06:03:17 +00:00
< VideoEmbed platform = "bilibili" id = "BV1vkNGehEun" / >
2025-03-10 14:40:37 +00:00
-- -
# # Approach 2 : Two - pass Hash Table
# # # Intuition
To improve our runtime complexity , we need a more efficient way to check if the complement exists in the array . If the complement exists , we need to get its index . What is the best way to maintain a mapping of each element in the array to its index ? A hash table .
We can reduce the lookup time from $O ( n ) $ to $O ( 1 ) $ by trading space for speed . A hash table is well suited for this purpose because it supports fast lookup in near constant time . I say "near" because if a collision occurred , a lookup could degenerate to $O ( n ) $ time . However , lookup in a hash table should be amortized $O ( 1 ) $ time as long as the hash function was chosen carefully .
# # # Algorithm
A simple implementation uses two iterations . In the first iteration , we add each element 's value as a key and its index as a value to the hash table. Then, in the second iteration, we check if each element' s complement ( $target - nums [ i ] $ ) exists in the hash table . If it does exist , we return current element 's index and its complement' s index . Beware that the complement must not be $nums [ i ] $ itself !
# # # Implementation
\ ` \` \` c showLineNumbers
int * twoSum ( int * nums , int numsSize , int target , int * returnSize ) {
struct hashTable {
int key ;
int value ;
UT_hash_handle hh ;
} * hashTable = NULL , * item , * tmpItem ;
for ( int i = 0 ; i < numsSize ; i ++ ) {
HASH_FIND_INT ( hashTable , & nums [ i ] , item ) ;
if ( item ) {
int * result = malloc ( sizeof ( int ) * 2 ) ;
result [ 0 ] = item - > value ;
result [ 1 ] = i ;
* returnSize = 2 ;
HASH_ITER ( hh , hashTable , item , tmpItem ) {
HASH_DEL ( hashTable , item ) ;
free ( item ) ;
}
return result ;
}
item = malloc ( sizeof ( struct hashTable ) ) ;
item - > key = target - nums [ i ] ;
item - > value = i ;
HASH_ADD_INT ( hashTable , key , item ) ;
}
HASH_ITER ( hh , hashTable , item , tmpItem ) {
HASH_DEL ( hashTable , item ) ;
free ( item ) ;
}
* returnSize = 0 ;
// If no valid pair is found, return an empty array
return malloc ( sizeof ( int ) * 0 ) ;
}
\ ` \` \`
# # # Complexity Analysis
- * * Time complexity : * * $O ( n ) $ .
We traverse the list containing $n $ elements exactly twice . Since the hash table reduces the lookup time to $O ( 1 ) $ , the overall time complexity is $O ( n ) $ .
- * * Space complexity : * * $O ( n ) $ .
The extra space required depends on the number of items stored in the hash table , which stores exactly $n $ elements .
-- -
# # Approach 3 : One - pass Hash Table
# # # Algorithm
It turns out we can do it in one - pass . While we are iterating and inserting elements into the hash table , we also look back to check if current element ' s complement already exists in the hash table . If it exists , we have found a solution and return the indices immediately .
# # # Implementation
\ ` \` \` c showLineNumbers
int * twoSum ( int * nums , int numsSize , int target , int * returnSize ) {
struct hashTable {
int key ;
int value ;
UT_hash_handle hh ;
} * hashTable = NULL , * item ;
for ( int i = 0 ; i < numsSize ; i ++ ) {
int complement = target - nums [ i ] ;
HASH_FIND_INT ( hashTable , & complement , item ) ;
if ( item ) {
int * result = malloc ( sizeof ( int ) * 2 ) ;
result [ 0 ] = item - > value ;
result [ 1 ] = i ;
* returnSize = 2 ;
HASH_CLEAR ( hh , hashTable ) ; // Free the hash table
return result ;
}
item = malloc ( sizeof ( struct hashTable ) ) ;
item - > key = nums [ i ] ;
item - > value = i ;
HASH_ADD_INT ( hashTable , key , item ) ;
}
* returnSize = 0 ;
HASH_CLEAR ( hh , hashTable ) ; // Free the hash table
// Return an empty array if no solution is found
return malloc ( 0 ) ; // Allocate 0 bytes
}
\ ` \` \`
# # # Complexity Analysis
- * * Time complexity : * * $O ( n ) $ .
We traverse the list containing $n $ elements only once . Each lookup in the table costs only $O ( 1 ) $ time .
- * * Space complexity : * * $O ( n ) $ .
The extra space required depends on the number of items stored in the hash table , which stores at most $n $ elements .
-- -
# # Summary of Approaches
| Approach | Time Complexity | Space Complexity |
| -- -- -- -- -- -- -- -- -- - | : -- -- -- -- -- -- - : | : -- -- -- -- -- -- -- : |
| Brute Force | $O ( n ^ 2 ) $ | $O ( 1 ) $ |
| Two - pass Hash Table | $O ( n ) $ | $O ( n ) $ |
| One - pass Hash Table | $O ( n ) $ | $O ( n ) $ | ` ,
2025-06-13 06:03:17 +00:00
} ,
{
locale : "zh" ,
type : "SOLUTION" ,
content : ` 
# # 方 法 一 : 暴 力 枚 举
# # # 算 法 思 路
暴 力 枚 举 法 的 思 路 很 简 单 : 遍 历 数 组 中 的 每 个 元 素 x , 并 查 找 是 否 存 在 另 一 个 元 素 的 值 等 于 $target - x $ .
# # # 代 码 实 现
\ ` \` \` c showLineNumbers {2-3,6-7,15}
int * twoSum ( int * nums , int numsSize , int target , int * returnSize ) {
for ( int i = 0 ; i < numsSize ; i ++ ) {
for ( int j = i + 1 ; j < numsSize ; j ++ ) {
if ( nums [ j ] == target - nums [ i ] ) {
int * result = malloc ( sizeof ( int ) * 2 ) ;
result [ 0 ] = i ;
result [ 1 ] = j ;
* returnSize = 2 ;
return result ;
}
}
}
// 如果未找到解,返回一个空数组
* returnSize = 0 ;
return malloc ( sizeof ( int ) * 0 ) ;
}
\ ` \` \`
# # # 复 杂 度 分 析
- * * 时 间 复 杂 度 : * * $O ( n ^ 2 ) $ .
对 于 数 组 中 的 每 个 元 素 , 我 们 都 要 通 过 遍 历 数 组 的 剩 余 部 分 来 查 找 它 的 补 数 , 这 需 要 $O ( n ) $ 的 时 间 。 因 此 , 总 的 时 间 复 杂 度 是 $O ( n ^ 2 ) $ .
- * * 空 间 复 杂 度 : \ ( O ( 1 ) \ ) * * $O ( 1 ) $ .
所 需 的 空 间 并 不 依 赖 于 输 入 数 组 的 大 小 , 所 以 只 使 用 了 常 数 级 别 的 空 间 。
< VideoEmbed platform = "bilibili" id = "BV1vkNGehEun" / >
-- -
# # 方 法 2 : 两遍哈希表
# # # 思 路
为 了 提 高 运 行 时 的 时 间 复 杂 度 , 我 们 需 要 一 种 更 高 效 的 方 法 来 检 查 数 组 中 是 否 存 在 某 个 元 素 的 补 数 。 如 果 补 数 存 在 , 我 们 还 需 要 获 取 它 的 索 引 。 维 护 数 组 中 每 个 元 素 与 其 索 引 之 间 的 映 射 的 最 佳 方 法 是 什 么 呢 ? 答 案 是 哈 希 表 。
我 们 可 以 通 过 用 空 间 换 取 时 间 的 方 式 , 将 查 找 时 间 从 $O ( n ) $ 降 低 到 $O ( 1 ) $ 。 哈 希 表 非 常 适 合 这 个 目 的 , 因 为 它 支 持 在 近 似 常 数 时 间 内 进 行 快 速 查 找 。 我 之 所 以 说 “ 近 似 ” , 是 因 为 如 果 发 生 了 哈 希 冲 突 , 查 找 时 间 可 能 会 退 化 为 $O ( n ) $ 。 不 过 , 只 要 精 心 选 择 哈 希 函 数 , 哈 希 表 的 查 找 时 间 平 均 为 $O ( 1 ) $ 。
# # # 算 法
一 种 简 单 的 实 现 方 式 是 使 用 两 次 迭 代 。 在 第 一 次 迭 代 中 , 我 们 将 每 个 元 素 的 值 作 为 键 , 其 索 引 作 为 值 添 加 到 哈 希 表 中 。 然 后 , 在 第 二 次 迭 代 中 , 我 们 检 查 每 个 元 素 的 补 数 ( $target - nums [ i ] $ ) 是 否 存 在 于 哈 希 表 中 。 如 果 存 在 , 我 们 就 返 回 当 前 元 素 的 索 引 和 它 补 数 的 索 引 。 需 要 注 意 的 是 , 补 数 不 能 是 元 素 本 身 $nums [ i ] $ !
# # # 代 码 实 现
\ ` \` \` c showLineNumbers
int * twoSum ( int * nums , int numsSize , int target , int * returnSize ) {
struct hashTable {
int key ;
int value ;
UT_hash_handle hh ;
} * hashTable = NULL , * item , * tmpItem ;
for ( int i = 0 ; i < numsSize ; i ++ ) {
HASH_FIND_INT ( hashTable , & nums [ i ] , item ) ;
if ( item ) {
int * result = malloc ( sizeof ( int ) * 2 ) ;
result [ 0 ] = item - > value ;
result [ 1 ] = i ;
* returnSize = 2 ;
HASH_ITER ( hh , hashTable , item , tmpItem ) {
HASH_DEL ( hashTable , item ) ;
free ( item ) ;
}
return result ;
}
item = malloc ( sizeof ( struct hashTable ) ) ;
item - > key = target - nums [ i ] ;
item - > value = i ;
HASH_ADD_INT ( hashTable , key , item ) ;
}
HASH_ITER ( hh , hashTable , item , tmpItem ) {
HASH_DEL ( hashTable , item ) ;
free ( item ) ;
}
* returnSize = 0 ;
// 如果没有找到有效的数对,则返回一个空数组
return malloc ( sizeof ( int ) * 0 ) ;
}
\ ` \` \`
# # # 复 杂 度 分 析
- * * 时 间 复 杂 度 : * * $O ( n ) $ .
我 们 精 确 地 遍 历 包 含 n 个 元 素 的 列 表 两 次 。 由 于 哈 希 表 将 查 找 时 间 减 少 到 $O ( 1 ) $ , 所 以 总 的 时 间 复 杂 度 为 $O ( n ) $ 。
- * * 空 间 复 杂 度 : * * $O ( n ) $ .
所 需 的 额 外 空 间 取 决 于 存 储 在 哈 希 表 中 的 元 素 数 量 , 而 哈 希 表 中 恰 好 存 储 了 $n $ 个 元 素 。
-- -
# # 方 法 三 : 一 遍 哈 希 表
# # # 算 法
事 实 证 明 , 我 们 可 以 通 过 一 遍 遍 历 实 现 。 在 我 们 遍 历 并 将 元 素 插 入 哈 希 表 的 同 时 , 我 们 还 要 检 查 当 前 元 素 的 补 数 是 否 已 经 存 在 于 哈 希 表 中 。 如 果 存 在 , 我 们 就 找 到 了 一 个 解 决 方 案 , 并 立 即 返 回 索 引 。
# # # 代 码 实 现
\ ` \` \` c showLineNumbers
int * twoSum ( int * nums , int numsSize , int target , int * returnSize ) {
struct hashTable {
int key ;
int value ;
UT_hash_handle hh ;
} * hashTable = NULL , * item ;
for ( int i = 0 ; i < numsSize ; i ++ ) {
int complement = target - nums [ i ] ;
HASH_FIND_INT ( hashTable , & complement , item ) ;
if ( item ) {
int * result = malloc ( sizeof ( int ) * 2 ) ;
result [ 0 ] = item - > value ;
result [ 1 ] = i ;
* returnSize = 2 ;
HASH_CLEAR ( hh , hashTable ) ; // 释放哈希表内存
return result ;
}
item = malloc ( sizeof ( struct hashTable ) ) ;
item - > key = nums [ i ] ;
item - > value = i ;
HASH_ADD_INT ( hashTable , key , item ) ;
}
* returnSize = 0 ;
HASH_CLEAR ( hh , hashTable ) ; // 释放哈希表内存
// 若未找到解,返回一个空数组
return malloc ( 0 ) ; // 分配0字节内存( )
}
\ ` \` \`
# # # 复 杂 度 分 析
- * * 时 间 复 杂 度 : * * $O ( n ) $ .
我 们 仅 遍 历 包 含 n 个 元 素 的 列 表 一 次 。 表 中 每 次 查 找 仅 需 $O ( 1 ) $ 时 间 。
- * * 空 间 复 杂 度 : * * $O ( n ) $ .
所 需 的 额 外 空 间 取 决 于 哈 希 表 中 存 储 的 元 素 数 量 , 该 哈 希 表 最 多 存 储 $n $ 个 元 素 。
-- -
# # 方 法 总 结
| 方 法 | 时 间 复 杂 度 | 空 间 复 杂 度 |
| -- -- -- -- -- -- -- -- -- - | : -- -- -- -- -- -- - : | : -- -- -- -- -- -- -- : |
| 暴 力 枚 举 | $O ( n ^ 2 ) $ | $O ( 1 ) $ |
| 两 遍 哈 希 表 | $O ( n ) $ | $O ( n ) $ |
| 一 遍 哈 希 表 | $O ( n ) $ | $O ( n ) $ | ` ,
} ,
] ,
} ,
templates : {
create : [
{
language : "c" ,
content : ` #include <stdio.h>
2025-04-09 13:13:26 +00:00
# include < stdlib.h >
# include < string.h >
2025-04-15 15:07:47 +00:00
/ * *
* Note : The returned array must be malloced , assume caller calls free ( ) .
* /
int * twoSum ( int * nums , int numsSize , int target , int * returnSize ) {
}
2025-04-09 13:13:26 +00:00
int * parseIntArray ( char * line , int * len ) {
line [ strcspn ( line , "\\n" ) ] = 0 ;
char * p = line ;
while ( * p && ( * p == '[' || * p == ' ' || * p == ']' ) )
p ++ ;
int capacity = 10 ;
int * arr = malloc ( capacity * sizeof ( int ) ) ;
* len = 0 ;
char * token = strtok ( p , "," ) ;
while ( token ) {
if ( * len >= capacity ) {
capacity *= 2 ;
arr = realloc ( arr , capacity * sizeof ( int ) ) ;
}
arr [ ( * len ) ++ ] = atoi ( token ) ;
token = strtok ( NULL , "," ) ;
}
return arr ;
}
char * formatOutput ( int * res , int resLen ) {
if ( resLen == 0 )
return "[]" ;
char * buf = malloc ( resLen * 12 + 3 ) ;
char * p = buf ;
* p ++ = '[' ;
for ( int i = 0 ; i < resLen ; i ++ ) {
p += sprintf ( p , "%d" , res [ i ] ) ;
if ( i != resLen - 1 )
* p ++ = ',' ;
}
* p ++ = ']' ;
* p = 0 ;
return buf ;
}
int main() {
char line [ 1024 ] ;
while ( fgets ( line , sizeof ( line ) , stdin ) ) {
int numsSize ;
int * nums = parseIntArray ( line , & numsSize ) ;
if ( ! fgets ( line , sizeof ( line ) , stdin ) )
break ;
int target = atoi ( line ) ;
int returnSize ;
int * res = twoSum ( nums , numsSize , target , & returnSize ) ;
char * output = formatOutput ( res , returnSize ) ;
printf ( "%s\\n" , output ) ;
free ( nums ) ;
if ( returnSize > 0 )
free ( res ) ;
if ( returnSize > 0 )
free ( output ) ;
}
return 0 ;
2025-03-09 09:45:13 +00:00
} ` ,
2025-06-13 06:03:17 +00:00
} ,
{
language : "cpp" ,
content : ` #include <iostream>
2025-04-15 12:50:49 +00:00
# include < sstream >
2025-04-15 15:07:47 +00:00
# include < string >
# include < vector >
2025-04-15 12:50:49 +00:00
using namespace std ;
class Solution {
2025-03-09 09:45:13 +00:00
public :
2025-04-15 15:07:47 +00:00
vector < int > twoSum ( vector < int > & nums , int target ) {
}
2025-04-15 12:50:49 +00:00
} ;
2025-04-15 15:07:47 +00:00
vector < int > parseIntArray ( const string & input ) {
vector < int > result ;
string trimmed = input . substr ( 1 , input . size ( ) - 2 ) ;
stringstream ss ( trimmed ) ;
string token ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
while ( getline ( ss , token , ',' ) ) {
result . push_back ( stoi ( token ) ) ;
}
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
return result ;
}
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
string formatOutput ( const vector < int > & output ) {
if ( output . empty ( ) )
return "[]" ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
stringstream ss ;
ss << "[" ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
for ( size_t i = 0 ; i < output . size ( ) ; ++ i ) {
ss << output [ i ] ;
if ( i != output . size ( ) - 1 )
ss << "," ;
}
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
ss << "]" ;
return ss . str ( ) ;
2025-04-15 12:50:49 +00:00
}
2025-04-15 15:07:47 +00:00
int main() {
string line ;
while ( getline ( cin , line ) ) {
vector < int > nums = parseIntArray ( line ) ;
getline ( cin , line ) ;
int target = stoi ( line ) ;
Solution sol ;
vector < int > result = sol . twoSum ( nums , target ) ;
cout << formatOutput ( result ) << endl ;
}
return 0 ;
} ` ,
2025-06-13 06:03:17 +00:00
} ,
] ,
} ,
testcases : {
create : [
{
inputs : {
create : [
{
index : 0 ,
name : "nums" ,
value : "[2,7,11,15]" ,
} ,
{
index : 1 ,
name : "target" ,
value : "9" ,
2025-03-09 09:45:13 +00:00
} ,
] ,
} ,
2025-06-13 06:03:17 +00:00
expectedOutput : "[0,1]" ,
} ,
{
inputs : {
2025-04-09 13:13:26 +00:00
create : [
{
2025-06-13 06:03:17 +00:00
index : 0 ,
name : "nums" ,
value : "[3,2,4]" ,
2025-04-09 13:13:26 +00:00
} ,
{
2025-06-13 06:03:17 +00:00
index : 1 ,
name : "target" ,
value : "6" ,
} ,
] ,
} ,
expectedOutput : "[1,2]" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "nums" ,
value : "[3,3]" ,
2025-04-09 13:13:26 +00:00
} ,
{
2025-06-13 06:03:17 +00:00
index : 1 ,
name : "target" ,
value : "6" ,
2025-04-09 13:13:26 +00:00
} ,
] ,
} ,
2025-06-13 06:03:17 +00:00
expectedOutput : "[0,1]" ,
} ,
] ,
} ,
} ,
{
displayId : 1001 ,
difficulty : "MEDIUM" ,
isPublished : true ,
2025-06-16 08:59:48 +00:00
isTrim : true ,
2025-06-13 06:03:17 +00:00
localizations : {
create : [
{
locale : "en" ,
type : "TITLE" ,
content : "Add Two Numbers" ,
2025-03-09 09:45:13 +00:00
} ,
{
2025-06-13 06:03:17 +00:00
locale : "zh" ,
type : "TITLE" ,
content : "两数相加" ,
} ,
{
locale : "en" ,
type : "DESCRIPTION" ,
content : ` You are given two **non-empty** linked lists representing two non-negative integers. The digits are stored in **reverse order**, and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
2025-03-09 09:45:13 +00:00
You may assume the two numbers do not contain any leading zero , except the number 0 itself .
# # Examples
# # # Example 1
2025-03-27 06:10:03 +00:00
! [ Example 1 ] ( https : //assets.leetcode.com/uploads/2020/10/02/addtwonumber1.jpg)
2025-03-09 09:45:13 +00:00
\ ` \` \` shell
Input : l1 = [ 2 , 4 , 3 ] , l2 = [ 5 , 6 , 4 ]
Output : [ 7 , 0 , 8 ]
Explanation : 342 + 465 = 807 .
\ ` \` \`
# # # Example 2
\ ` \` \` shell
Input : l1 = [ 0 ] , l2 = [ 0 ]
Output : [ 0 ]
\ ` \` \`
# # # Example 3
\ ` \` \` shell
Input : l1 = [ 9 , 9 , 9 , 9 , 9 , 9 , 9 ] , l2 = [ 9 , 9 , 9 , 9 ]
Output : [ 8 , 9 , 9 , 9 , 0 , 0 , 0 , 1 ]
\ ` \` \`
# # Constraints
< div align = "center" >
The number of nodes in each linked list is in the range $ [ 1 , 100 ] $ .
< / div >
\ ` \` \` math
0 <= Node . val <= 9
\ ` \` \`
< div align = "center" >
It is guaranteed that the list represents a number that does not have leading zeros .
< / div > ` ,
2025-06-13 06:03:17 +00:00
} ,
{
locale : "zh" ,
type : "DESCRIPTION" ,
content : ` 给定两个**非空**链表,它们表示两个非负整数。这些数字以**逆序**存储,并且每个节点包含一个数字。将这两个数字相加,并以链表形式返回它们的和。
你 可 以 假 设 这 两 个 数 字 除 了 数 字 0 本 身 外 , 不 包 含 任 何 前 导 零 。
# # 示 例
# # # 示 例 1
! [ 示 例 1 ] ( https : //assets.leetcode.com/uploads/2020/10/02/addtwonumber1.jpg)
\ ` \` \` shell
输入 : l1 = [ 2 , 4 , 3 ] , l2 = [ 5 , 6 , 4 ]
输 出 : [ 7 , 0 , 8 ]
解释 : 342 + 465 = 807 .
\ ` \` \`
# # # 示 例 2
\ ` \` \` shell
输入 : l1 = [ 0 ] , l2 = [ 0 ]
输 出 : [ 0 ]
\ ` \` \`
# # # 示 例 3
\ ` \` \` shell
输入 : l1 = [ 9 , 9 , 9 , 9 , 9 , 9 , 9 ] , l2 = [ 9 , 9 , 9 , 9 ]
输 出 : [ 8 , 9 , 9 , 9 , 0 , 0 , 0 , 1 ]
\ ` \` \`
# # 约 束 条 件
< div align = "center" >
每 个 链 表 中 的 节 点 数 范 围 是 e $ [ 1 , 100 ] $ .
< / div >
\ ` \` \` math
0 <= 节 点 值 <= 9
\ ` \` \`
< div align = "center" >
保 证 链 表 表 示 的 数 字 无 前 导 零 。
< / div > ` ,
} ,
{
locale : "en" ,
type : "SOLUTION" ,
content : ` ## Approach 1: Elementary Math
2025-03-10 14:40:37 +00:00
# # # Intuition
Keep track of the carry using a variable and simulate digits - by - digits sum starting from the head of list , which contains the least - significant digit .
2025-03-27 06:10:03 +00:00
! [ Figure 1 ] ( https : //leetcode.com/problems/add-two-numbers/Figures/2_add_two_numbers.svg)
2025-03-10 14:40:37 +00:00
* Figure 1 . Visualization of the addition of two numbers : $342 + 465 = 807 $ . *
* Each node contains a single digit and the digits are stored in reverse order . *
# # # Algorithm
Just like how you would sum two numbers on a piece of paper , we begin by summing the least - significant digits , which is the head of $l1 $ and $l2 $ . Since each digit is in the range of $0 … 9 $ , summing two digits may "overflow" . For example $5 + 7 = 12 $ . In this case , we set the current digit to $2 $ and bring over the $carry = 1 $ to the next iteration . $carry $ must be either $0 $ or $1 $ because the largest possible sum of two digits ( including the carry ) is $9 + 9 + 1 = 19 $ .
The pseudocode is as following :
- Initialize current node to dummy head of the returning list .
- Initialize carry to $0 $ .
- Loop through lists $l1 $ and $l2 $ until you reach both ends and carry is $0 $ .
- Set $x $ to node $l1 $ ' s value . If $l1 $ has reached the end of $l1 $ , set to $0 $ .
- Set $y $ to node $l2 $ ' s value . If $l2 $ has reached the end of $l2 $ , set to $0 $ .
- Set $sum = x + y + carry $ .
- Update $carry = sum / 10 $ .
- Create a new node with the digit value of ( $sum $ $mod $ $10 $ ) and set it to current node ' s next , then advance current node to next .
- Advance both $l1 $ and $l2 $ .
- Return dummy head ' s next node .
Note that we use a dummy head to simplify the code . Without a dummy head , you would have to write extra conditional statements to initialize the head ' s value .
Take extra caution of the following cases :
| Test case | Explanation |
| -- -- -- -- -- -- -- -- -- -- -- - | -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- - |
| l1 = [ 0 , 1 ] < br / > l2 = [ 0 , 1 , 2 ] | When one list is longer than the other . |
| l1 = [ ] < br / > l2 = [ 0 , 1 ] | When one list is null , which means an empty list . |
| l1 = [ 9 , 9 ] < br / > l2 = [ 1 ] | The sum could have an extra carry of one at the end , which is easy to forget . |
# # # Implementation
\ ` \` \` c showLineNumbers
struct ListNode * addTwoNumbers ( struct ListNode * l1 , struct ListNode * l2 ) {
struct ListNode * dummyHead = malloc ( sizeof ( struct ListNode ) ) ;
dummyHead - > val = 0 ;
dummyHead - > next = NULL ;
struct ListNode * curr = dummyHead ;
int carry = 0 ;
while ( l1 != NULL || l2 != NULL || carry != 0 ) {
int x = ( l1 != NULL ) ? l1 - > val : 0 ;
int y = ( l2 != NULL ) ? l2 - > val : 0 ;
int sum = carry + x + y ;
carry = sum / 10 ;
curr - > next = malloc ( sizeof ( struct ListNode ) ) ;
curr - > next - > val = sum % 10 ;
curr - > next - > next = NULL ;
curr = curr - > next ;
if ( l1 != NULL ) l1 = l1 - > next ;
if ( l2 != NULL ) l2 = l2 - > next ;
}
struct ListNode * result = dummyHead - > next ;
free ( dummyHead ) ; // Free the memory allocated for dummyHead
return result ;
}
\ ` \` \`
# # # Complexity Analysis
- * * Time complexity : * * $O ( max ( m , n ) ) $
Assume that $m $ and $n $ represents the length of $l1 $ and $l2 $ respectively , the algorithm above iterates at most $max ( m , n ) $ times .
- * * Space complexity : * * $O ( 1 ) $
The length of the new list is at most $max ( m , n ) + 1 $ However , we don ' t count the answer as part of the space complexity .
# # # Follow up
What if the the digits in the linked list are stored in non - reversed order ? For example :
$ ( 3 → 4 → 2 ) + ( 4 → 6 → 5 ) = 8 → 0 → 7 $ ` ,
2025-06-13 06:03:17 +00:00
} ,
{
locale : "zh" ,
type : "SOLUTION" ,
content : ` ## 方法 1:
# # # 思 路
使 用 一 个 变 量 跟 踪 进 位 , 并 从 链 表 头 部 ( 存 储 最 低 有 效 位 ) 开 始 逐 位 模 拟 数 字 相 加 。
! [ Figure 1 ] ( https : //leetcode.com/problems/add-two-numbers/Figures/2_add_two_numbers.svg)
* 图 1 . 两 数 相 加 的 可 视 化 过 程 : $342 + 465 = 807 $ . *
* 每 个 节 点 包 含 一 个 数 字 , 且 数 字 按 逆 序 存 储 *
# # # 算 法
就 像 在 纸 上 计 算 两 数 相 加 一 样 , 我 们 从 最 低 有 效 位 ( 即 $l1 $ 和 $l2 $ 的 头 部 ) 开 始 逐 位 相 加 。 由 于 每 个 数 字 在 $0 … 9 $ 范 围 内 , 两 数 相 加 可 能 会 产 生 “ 进 位 ” 。 例 如 $5 + 7 = 12 $ , 此 时 当 前 位 设 为 $2 $ , 并 将 进 位 $carry = 1 $ 带 入 下 一 次 计 算 。 进 位 $carry $ 只 能 是 $0 $ 或 $1 $ , 因 为 两 个 数 字 ( 含 进 位 ) 的 最 大 和 为 $9 + 9 + 1 = 19 $ .
伪 代 码 如 下 :
- 初 始 化 当 前 节 点 为 返 回 链 表 的 哑 结 点 ( dummy head ) 。
- 初 始 化 进 位 carry 为 $0 $ .
- 遍 历 链 表 $l1 $ 和 $l2 $ , 直 到 两 链 表 均 遍 历 完 毕 且 进 位 为 $0 $ .
- 设 $x $ 为 $l1 $ 当 前 节 点 的 值 , 若 $l1 $ 已 遍 历 结 束 则 设 为 $0 $ .
- 设 $y $ 为 $l2 $ 当 前 节 点 的 值 , 若 $l2 $ 已 遍 历 结 束 则 设 为 $0 $ .
- 计 算 总 和 $sum = x + y + carry $ .
- 更 新 进 位 $carry = sum / 10 $ .
- 创 建 新 节 点 , 值 为 $sum $ $mod $ $10 $ , 连 接 到 当 前 节 点 的 下 一 个 位 置 , 并 将 当 前 节 点 后 移 。
- 同 时 后 移 $l1 $ 和 $l2 $ 指 针 ( 若 未 遍 历 结 束 ) 。
- 返 回 哑 结 点 的 下 一 个 节 点 ( 即 实 际 链 表 的 头 节 点 ) 。
说 明 : 使 用 哑 结 点 可 简 化 代 码 逻 辑 。 若 无 哑 结 点 , 需 额 外 处 理 头 节 点 的 初 始 化 条 件 。
需 特 别 注 意 以 下 测 试 用 例 :
| 测 试 用 例 | 说 明 |
| -- -- -- -- -- -- -- -- -- -- -- - | -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- - |
| l1 = [ 0 , 1 ] < br / > l2 = [ 0 , 1 , 2 ] | 其 中 一 个 链 表 较 长 的 情 况 。 |
| l1 = [ ] < br / > l2 = [ 0 , 1 ] | 链 表 为 空 的 情 况 ( 等 价 于 数 字 0 ) 。 |
| l1 = [ 9 , 9 ] < br / > l2 = [ 1 ] | 末 尾 相 加 后 仍 有 进 位 的 情 况 ( 易 遗 漏 最 终 进 位 ) 。 |
# # # 实 现
\ ` \` \` c showLineNumbers
struct ListNode * addTwoNumbers ( struct ListNode * l1 , struct ListNode * l2 ) {
struct ListNode * dummyHead = malloc ( sizeof ( struct ListNode ) ) ;
dummyHead - > val = 0 ;
dummyHead - > next = NULL ;
struct ListNode * curr = dummyHead ;
int carry = 0 ;
while ( l1 != NULL || l2 != NULL || carry != 0 ) {
int x = ( l1 != NULL ) ? l1 - > val : 0 ;
int y = ( l2 != NULL ) ? l2 - > val : 0 ;
int sum = carry + x + y ;
carry = sum / 10 ;
curr - > next = malloc ( sizeof ( struct ListNode ) ) ;
curr - > next - > val = sum % 10 ;
curr - > next - > next = NULL ;
curr = curr - > next ;
if ( l1 != NULL ) l1 = l1 - > next ;
if ( l2 != NULL ) l2 = l2 - > next ;
}
struct ListNode * result = dummyHead - > next ;
free ( dummyHead ) ; // 释放为哑结点( )
return result ;
}
\ ` \` \`
# # # 复 杂 度 分 析
- * * 时 间 复 杂 度 : * * $O ( max ( m , n ) ) $
假 设 $m $ 和 $n $ 分 别 表 示 链 表 $l1 $ 和 $l2 $ 的 长 度 , 上 述 算 法 最 多 迭 代 $max ( m , n ) $ 次 。
- * * 空 间 复 杂 度 : * * $O ( 1 ) $
新 链 表 的 长 度 最 多 为 $max ( m , n ) + 1 $ , 但 我 们 通 常 不 将 结 果 链 表 计 入 空 间 复 杂 度 分 析 。
# # # 后 续 问 题
如 果 链 表 中 的 数 字 以 非 逆 序 ( 正 序 ) 存 储 , 该 如 何 处 理 ? 例 如 :
$ ( 3 → 4 → 2 ) + ( 4 → 6 → 5 ) = 8 → 0 → 7 $ ` ,
} ,
] ,
} ,
templates : {
create : [
{
language : "c" ,
content : ` #include <stdio.h>
2025-04-15 12:50:49 +00:00
# include < stdlib.h >
# include < string.h >
struct ListNode {
2025-04-15 15:07:47 +00:00
int val ;
struct ListNode * next ;
2025-04-15 12:50:49 +00:00
} ;
2025-04-15 15:07:47 +00:00
struct ListNode * addTwoNumbers ( struct ListNode * l1 , struct ListNode * l2 ) {
2025-04-15 12:50:49 +00:00
}
2025-04-15 15:07:47 +00:00
struct ListNode * parseList ( char * line ) {
line [ strcspn ( line , "\\n" ) ] = 0 ;
char * p = line ;
while ( * p && ( * p == '[' || * p == ' ' || * p == ']' ) )
p ++ ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
struct ListNode dummy ;
struct ListNode * cur = & dummy ;
dummy . next = NULL ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
char * token = strtok ( p , "," ) ;
while ( token ) {
struct ListNode * node = malloc ( sizeof ( struct ListNode ) ) ;
node - > val = atoi ( token ) ;
node - > next = NULL ;
cur - > next = node ;
cur = node ;
token = strtok ( NULL , "," ) ;
}
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
return dummy . next ;
}
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
void printList ( struct ListNode * head ) {
printf ( "[" ) ;
while ( head ) {
printf ( "%d" , head - > val ) ;
head = head - > next ;
if ( head )
printf ( "," ) ;
}
printf ( "]\\n" ) ;
}
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
void freeList ( struct ListNode * head ) {
while ( head ) {
struct ListNode * tmp = head ;
head = head - > next ;
free ( tmp ) ;
}
2025-04-15 12:50:49 +00:00
}
2025-04-15 15:07:47 +00:00
int main() {
char line [ 1024 ] ;
while ( fgets ( line , sizeof ( line ) , stdin ) ) {
struct ListNode * l1 = parseList ( line ) ;
if ( ! fgets ( line , sizeof ( line ) , stdin ) )
break ;
struct ListNode * l2 = parseList ( line ) ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
struct ListNode * result = addTwoNumbers ( l1 , l2 ) ;
printList ( result ) ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
freeList ( l1 ) ;
freeList ( l2 ) ;
freeList ( result ) ;
}
return 0 ;
} ` ,
2025-06-13 06:03:17 +00:00
} ,
{
language : "cpp" ,
content : ` #include <algorithm>
2025-04-15 12:50:49 +00:00
# include < iostream >
# include < sstream >
2025-04-15 15:07:47 +00:00
# include < string >
2025-04-15 12:50:49 +00:00
using namespace std ;
struct ListNode {
2025-04-15 15:07:47 +00:00
int val ;
ListNode * next ;
ListNode ( ) : val ( 0 ) , next ( nullptr ) { }
ListNode ( int x ) : val ( x ) , next ( nullptr ) { }
ListNode ( int x , ListNode * next ) : val ( x ) , next ( next ) { }
2025-04-15 12:50:49 +00:00
} ;
2025-03-09 09:45:13 +00:00
class Solution {
public :
2025-04-15 15:07:47 +00:00
ListNode * addTwoNumbers ( ListNode * l1 , ListNode * l2 ) {
}
2025-04-15 12:50:49 +00:00
} ;
2025-04-15 15:07:47 +00:00
ListNode * createList ( const string & line ) {
ListNode dummy ;
ListNode * tail = & dummy ;
dummy . next = nullptr ;
string nums = line ;
nums . erase ( remove ( nums . begin ( ) , nums . end ( ) , '[' ) , nums . end ( ) ) ;
nums . erase ( remove ( nums . begin ( ) , nums . end ( ) , ']' ) , nums . end ( ) ) ;
stringstream ss ( nums ) ;
string token ;
while ( getline ( ss , token , ',' ) ) {
if ( ! token . empty ( ) ) {
int val = stoi ( token ) ;
tail - > next = new ListNode ( val ) ;
tail = tail - > next ;
2025-04-15 12:50:49 +00:00
}
2025-04-15 15:07:47 +00:00
}
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
return dummy . next ;
2025-04-15 12:50:49 +00:00
}
2025-04-15 15:07:47 +00:00
void printList ( ListNode * head ) {
cout << "[" ;
while ( head ) {
cout << head - > val ;
if ( head - > next )
cout << "," ;
head = head - > next ;
}
cout << "]" << endl ;
2025-04-15 12:50:49 +00:00
}
2025-04-15 15:07:47 +00:00
void freeList ( ListNode * head ) {
while ( head ) {
ListNode * tmp = head ;
head = head - > next ;
delete tmp ;
}
2025-04-15 12:50:49 +00:00
}
int main() {
2025-04-15 15:07:47 +00:00
string line ;
while ( getline ( cin , line ) ) {
ListNode * l1 = createList ( line ) ;
if ( ! getline ( cin , line ) )
break ;
ListNode * l2 = createList ( line ) ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
Solution sol ;
ListNode * res = sol . addTwoNumbers ( l1 , l2 ) ;
printList ( res ) ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
freeList ( l1 ) ;
freeList ( l2 ) ;
freeList ( res ) ;
}
return 0 ;
} ` ,
2025-06-13 06:03:17 +00:00
} ,
] ,
} ,
testcases : {
create : [
{
inputs : {
create : [
{
index : 0 ,
name : "l1" ,
value : "[2,4,3]" ,
} ,
{
index : 1 ,
name : "l2" ,
value : "[5,6,4]" ,
2025-03-09 09:45:13 +00:00
} ,
] ,
} ,
2025-06-13 06:03:17 +00:00
expectedOutput : "[7,0,8]" ,
} ,
{
inputs : {
2025-04-09 13:13:26 +00:00
create : [
{
2025-06-13 06:03:17 +00:00
index : 0 ,
name : "l1" ,
value : "[0]" ,
2025-04-09 13:13:26 +00:00
} ,
{
2025-06-13 06:03:17 +00:00
index : 1 ,
name : "l2" ,
value : "[0]" ,
2025-04-09 13:13:26 +00:00
} ,
2025-06-13 06:03:17 +00:00
] ,
} ,
expectedOutput : "[0]" ,
} ,
{
inputs : {
create : [
2025-04-09 13:13:26 +00:00
{
2025-06-13 06:03:17 +00:00
index : 0 ,
name : "l1" ,
value : "[9,9,9,9,9,9,9]" ,
} ,
{
index : 1 ,
name : "l2" ,
value : "[9,9,9,9]" ,
2025-04-09 13:13:26 +00:00
} ,
] ,
} ,
2025-06-13 06:03:17 +00:00
expectedOutput : "[8,9,9,9,0,0,0,1]" ,
2025-03-09 09:45:13 +00:00
} ,
] ,
} ,
} ,
{
2025-06-13 06:03:17 +00:00
displayId : 1002 ,
difficulty : "HARD" ,
isPublished : true ,
2025-06-16 08:59:48 +00:00
isTrim : true ,
2025-06-13 06:03:17 +00:00
localizations : {
2025-03-09 09:45:13 +00:00
create : [
{
2025-06-13 06:03:17 +00:00
locale : "en" ,
type : "TITLE" ,
content : "Median of Two Sorted Arrays" ,
} ,
{
locale : "zh" ,
type : "TITLE" ,
content : "寻找两个正序数组的中位数" ,
} ,
{
locale : "en" ,
type : "DESCRIPTION" ,
content : ` Given two sorted arrays \` nums1 \` and \` nums2 \` of size \` m \` and \` n \` respectively, return **the median** of the two sorted arrays.
2025-03-09 09:45:13 +00:00
The overall run time complexity should be $O ( log ( m + n ) ) $ .
# # Examples
# # # Example 1
\ ` \` \` shell
Input : nums1 = [ 1 , 3 ] , nums2 = [ 2 ]
Output : 2.00000
Explanation : merged array = [ 1 , 2 , 3 ] and median is 2 .
\ ` \` \`
# # # Example 2
\ ` \` \` shell
Input : nums1 = [ 1 , 2 ] , nums2 = [ 3 , 4 ]
Output : 2.50000
Explanation : merged array = [ 1 , 2 , 3 , 4 ] and median is ( 2 + 3 ) / 2 = 2.5 .
\ ` \` \`
# # Constraints
\ ` \` \` math
nums_1 . length == m
\ ` \` \`
\ ` \` \` math
nums_2 . length == n
\ ` \` \`
\ ` \` \` math
0 <= m <= 1000
\ ` \` \`
\ ` \` \` math
0 <= n <= 1000
\ ` \` \`
\ ` \` \` math
1 <= m + n <= 2000
\ ` \` \`
\ ` \` \` math
- 10 ^ 6 <= nums_1 [ i ] , nums_2 [ i ] <= 10 ^ 6
\ ` \` \` ` ,
2025-06-13 06:03:17 +00:00
} ,
{
locale : "zh" ,
type : "DESCRIPTION" ,
content : ` 给定两个大小分别为 \` nums1 \` 和 \` nums2 \` 的有序数组 \` m \` 和 \` n \` ,请返回这两个有序数组的**中位数**。
要 求 整 体 时 间 复 杂 度 为 $O ( log ( m + n ) ) $ .
# # 示 例
# # # 示 例 1
\ ` \` \` shell
Input : nums1 = [ 1 , 3 ] , nums2 = [ 2 ]
Output : 2.00000
Explanation : merged array = [ 1 , 2 , 3 ] and median is 2 .
\ ` \` \`
# # # 示 例 2
\ ` \` \` shell
Input : nums1 = [ 1 , 2 ] , nums2 = [ 3 , 4 ]
Output : 2.50000
Explanation : merged array = [ 1 , 2 , 3 , 4 ] and median is ( 2 + 3 ) / 2 = 2.5 .
\ ` \` \`
# # 约 束 条 件
\ ` \` \` math
nums_1 . length == m
\ ` \` \`
\ ` \` \` math
nums_2 . length == n
\ ` \` \`
\ ` \` \` math
0 <= m <= 1000
\ ` \` \`
\ ` \` \` math
0 <= n <= 1000
\ ` \` \`
\ ` \` \` math
1 <= m + n <= 2000
\ ` \` \`
\ ` \` \` math
- 10 ^ 6 <= nums_1 [ i ] , nums_2 [ i ] <= 10 ^ 6
\ ` \` \` ` ,
} ,
{
locale : "en" ,
type : "SOLUTION" ,
content : ` ## Approach 1: Merge Sort
2025-03-10 14:40:37 +00:00
# # # Intuition
Let ' s start with the straightforward approach . If we put the elements of two arrays in one array \ ` A \` and arrange them in order. Assume the merged arrays has a length of \` n \` , then the median is:
- \ ` A[n / 2] \` , if \` n \` is odd.
- The average of \ ` A[n / 2] \` and \` A[n / 2 + 1] \` , if \` n \` is even.
However , we do not really need to merge and sort these arrays . Note that both arrays are already sorted , so the smallest element is either the first element of \ ` nums1 \` or the first element of \` nums2 \` . Therefore, we can set two pointers \` p1 \` and \` p2 \` at the start of each array, then we can get the smallest element from the \` nums1 \` and \` nums2 \` by comparing the values \` nums1[p1] \` and \` nums2[p2] \` .
Please refer to the following slide as an example :
# # # Algorithm
1 . Get the total size of two arrays \ ` m + n \`
- If \ ` m + n \` is odd, we are looking for the \` (m + n) / 2 \` -th element.
- If \ ` m + n \` is even, we are looking for the average of the \` (m + n) / 2 \` -th and the \` (m + n) / 2 + 1 \` -th elements.
2 . Set two pointers \ ` p1 \` and \` p2 \` at the beginning of arrays \` nums1 \` and \` nums2 \` .
3 . If both \ ` p1 \` and \` p2 \` are in bounds of the arrays, compare the values at \` p1 \` and \` p2 \` :
- If \ ` nums1[p1] \` is smaller than \` nums2[p2] \` , we move \` p1 \` one place to the right.
- Otherwise , we move \ ` p2 \` one place to the right.
If \ ` p1 \` is outside \` nums1 \` , just move \` p2 \` one place to the right.
If \ ` p2 \` is outside \` nums2 \` , just move \` p1 \` one place to the right.
4 . Get the target elements and calculate the median :
- If \ ` m + n \` is odd, repeat step 3 by \` (m + n + 1) / 2 \` times and return the element from the last step.
- If \ ` m + n \` is even, repeat step 3 by \` (m + n) / 2 + 1 \` times and return the average of the elements from the last two steps.
# # # Implementation
\ ` \` \` c showLineNumbers
double findMedianSortedArrays ( int * nums1 , int nums1Size , int * nums2 , int nums2Size ) {
int m = nums1Size , n = nums2Size ;
int p1 = 0 , p2 = 0 ;
int getMin() {
if ( p1 < m && p2 < n ) {
return nums1 [ p1 ] < nums2 [ p2 ] ? nums1 [ p1 ++ ] : nums2 [ p2 ++ ] ;
} else if ( p1 < m ) {
return nums1 [ p1 ++ ] ;
} else if ( p2 < n ) {
return nums2 [ p2 ++ ] ;
}
return - 1 ;
}
double median ;
if ( ( m + n ) % 2 == 0 ) {
for ( int i = 0 ; i < ( ( m + n ) / 2 ) - 1 ; ++ i ) {
int temp = getMin ( ) ;
}
median = ( getMin ( ) + getMin ( ) ) / 2.0 ;
} else {
for ( int i = 0 ; i < ( m + n ) / 2 ; ++ i ) {
int temp = getMin ( ) ;
}
median = getMin ( ) ;
}
return median ;
}
\ ` \` \`
# # # Complexity Analysis
Let $m $ be the size of array \ ` nums1 \` and $ n $ be the size of array \` nums2 \` .
- * * Time complexity : * * $O ( m + n ) $
- We get the smallest element by comparing two values at \ ` p1 \` and \` p2 \` , it takes $ O(1) $ to compare two elements and move the corresponding pointer to the right.
- We need to traverse half of the arrays before reaching the median element ( s ) .
- To sum up , the time complexity is $O ( m + n ) $ .
- * * Space complexity : * * $O ( 1 ) $
- We only need to maintain two pointers \ ` p1 \` and \` p2 \` . ` ,
2025-06-13 06:03:17 +00:00
} ,
{
locale : "zh" ,
type : "SOLUTION" ,
content : ` ## 方法 1: 归并排序思路
# # # 思 路
我 们 从 最 直 接 的 方 法 开 始 思 考 。 如 果 将 两 个 数 组 合 并 成 一 个 数 组 \ ` A \` 并排序,假设合并后数组的长度为 \` n \` ,那么中位数为:
- 当 n 为 奇 数 时 , 中 位 数 是 \ ` A[n / 2] \` 。
- 当 n 为 偶 数 时 , 中 位 数 是 \ ` A[n / 2] \` 和 \` A[n / 2 + 1] \` 的平均值。
不 过 , 我 们 实 际 上 不 需 要 真 正 合 并 和 排 序 数 组 。 注 意 到 两 个 数 组 已 经 是 有 序 的 , 因 此 最 小 的 元 素 一 定 是 \ ` nums1 \` 或 \` nums2 \` 。 因此,我们可以设置两个指针 \` p1 \` 和 \` p2 \` 分别指向两个数组的起始位置,通过比较 \` nums1[p1] \` 和 \` nums2[p2] \` 的值来逐步获取合并后的有序元素。
以 下 面 的 示 例 流 程 为 例 ( 可 参 考 对 应 图 示 ) :
# # # 算 法
1 . 计 算 两 个 数 组 的 总 长 度 \ ` m + n \`
- 若 \ ` m + n \` 为奇数,我们需要找到第 \` (m + n) / 2 \` 个元素(从 0 开始计数)。
- 若 \ ` m + n \` 为偶数,我们需要找到第 \` (m + n) / 2 \` 个和第 \` (m + n) / 2 + 1 \` 个元素的平均值。
2 . 初 始 化 指 针 \ ` p1 \` = 0( \` nums1 \` 起始)和 \` p2 \` = 0( \` nums2 \` 起始)。
3 . 如 果 \ ` p1 \` 和 \` p2 \` 都在数组的有效范围内(即未越界),则比较 \` p1 \` 和 \` p2 \` 所指位置的值:
- 如 果 \ ` nums1[p1] \` 小于 \` nums2[p2] \` ,则将 \` p1 \` 向右移动一位。
- 否 则 , 将 \ ` p2 \` 向右移动一位。
如 果 \ ` p1 \` 超出 \` nums1 \` 的范围,则直接将 \` p2 \` 向右移动一位。
如 果 \ ` p2 \` 超出 \` nums2 \` 的范围,则直接将 \` p1 \` 向右移动一位。
4 . 获 取 目 标 元 素 并 计 算 中 位 数 :
- 若 \ ` m + n \` 为奇数,重复步骤 \` 3 (m + n + 1) / 2 \` 次(每次移动指针对应获取一个元素),最后一次步骤中得到的元素即为中位数。
- 若 \ ` m + n \` 为偶数,重复步骤 \` 3 (m + n) / 2 + 1 \` 次,取最后两次步骤中得到的元素,计算它们的平均值作为中位数。
# # # 实 现
\ ` \` \` c showLineNumbers
double findMedianSortedArrays ( int * nums1 , int nums1Size , int * nums2 , int nums2Size ) {
int m = nums1Size , n = nums2Size ;
int p1 = 0 , p2 = 0 ;
int getMin() {
if ( p1 < m && p2 < n ) {
return nums1 [ p1 ] < nums2 [ p2 ] ? nums1 [ p1 ++ ] : nums2 [ p2 ++ ] ;
} else if ( p1 < m ) {
return nums1 [ p1 ++ ] ;
} else if ( p2 < n ) {
return nums2 [ p2 ++ ] ;
}
return - 1 ;
}
double median ;
if ( ( m + n ) % 2 == 0 ) {
for ( int i = 0 ; i < ( ( m + n ) / 2 ) - 1 ; ++ i ) {
int temp = getMin ( ) ;
}
median = ( getMin ( ) + getMin ( ) ) / 2.0 ;
} else {
for ( int i = 0 ; i < ( m + n ) / 2 ; ++ i ) {
int temp = getMin ( ) ;
}
median = getMin ( ) ;
}
return median ;
}
\ ` \` \`
# # # 复 杂 度 分 析
设 数 组 \ ` nums1 \` 的长度为 $ m $ ,数组 \` nums2 \` 的长度为 $ n $ 。
- * * 时 间 复 杂 度 : * * $O ( m + n ) $
- 我 们 通 过 比 较 \ ` p1 \` 和 \` p2 \` 指向的两个元素来获取当前最小元素,每次比较和移动指针的时间为 $ O(1) $ 。
- 在 找 到 中 位 数 元 素 ( 或 元 素 对 ) 之 前 , 需 要 遍 历 两 个 数 组 中 最 多 一 半 的 元 素 。
- 综 上 , 总 时 间 复 杂 度 为 $O ( m + n ) $ .
- * * 空 间 复 杂 度 : * * $O ( 1 ) $
- 仅 需 维 护 两 个 指 针 \ ` p1 \` 和 \` p2 \` ,无需额外线性空间。 ` ,
} ,
] ,
} ,
templates : {
create : [
{
language : "c" ,
content : ` #include <stdio.h>
2025-04-15 12:50:49 +00:00
# include < stdlib.h >
# include < string.h >
2025-04-15 15:07:47 +00:00
double findMedianSortedArrays ( int * nums1 , int nums1Size , int * nums2 , int nums2Size ) {
2025-04-15 12:50:49 +00:00
}
2025-04-15 15:07:47 +00:00
int * parseIntArray ( char * line , int * len ) {
line [ strcspn ( line , "\\n" ) ] = 0 ;
char * p = line ;
while ( * p && ( * p == '[' || * p == ' ' || * p == ']' ) )
p ++ ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
int capacity = 10 ;
int * arr = malloc ( capacity * sizeof ( int ) ) ;
* len = 0 ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
char * token = strtok ( p , "," ) ;
while ( token ) {
if ( * len >= capacity ) {
capacity *= 2 ;
arr = realloc ( arr , capacity * sizeof ( int ) ) ;
}
arr [ ( * len ) ++ ] = atoi ( token ) ;
token = strtok ( NULL , "," ) ;
}
return arr ;
}
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
int main() {
char line [ 1024 ] ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
while ( fgets ( line , sizeof ( line ) , stdin ) ) {
int nums1Size ;
int * nums1 = parseIntArray ( line , & nums1Size ) ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
if ( ! fgets ( line , sizeof ( line ) , stdin ) )
break ;
int nums2Size ;
int * nums2 = parseIntArray ( line , & nums2Size ) ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
double result = findMedianSortedArrays ( nums1 , nums1Size , nums2 , nums2Size ) ;
printf ( "%.5f\\n" , result ) ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
free ( nums1 ) ;
free ( nums2 ) ;
}
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
return 0 ;
} ` ,
2025-06-13 06:03:17 +00:00
} ,
{
language : "cpp" ,
content : ` #include <iostream>
2025-04-15 12:50:49 +00:00
# include < sstream >
2025-04-15 15:07:47 +00:00
# include < string >
# include < vector >
2025-04-15 12:50:49 +00:00
using namespace std ;
class Solution {
2025-03-09 09:45:13 +00:00
public :
2025-04-15 15:07:47 +00:00
double findMedianSortedArrays ( vector < int > & nums1 , vector < int > & nums2 ) {
}
2025-04-15 12:50:49 +00:00
} ;
2025-04-15 15:07:47 +00:00
vector < int > parseVector ( const string & line ) {
vector < int > result ;
stringstream ss ( line ) ;
char c ;
int num ;
while ( ss >> c ) {
if ( isdigit ( c ) || c == '-' || c == '+' ) {
ss . putback ( c ) ;
ss >> num ;
result . push_back ( num ) ;
2025-04-15 12:50:49 +00:00
}
2025-04-15 15:07:47 +00:00
}
return result ;
2025-04-15 12:50:49 +00:00
}
int main() {
2025-04-15 15:07:47 +00:00
string line ;
while ( getline ( cin , line ) ) {
vector < int > nums1 = parseVector ( line ) ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
if ( ! getline ( cin , line ) )
break ;
vector < int > nums2 = parseVector ( line ) ;
2025-04-15 12:50:49 +00:00
2025-04-15 15:07:47 +00:00
Solution sol ;
double result = sol . findMedianSortedArrays ( nums1 , nums2 ) ;
printf ( "%.5f\\n" , result ) ;
}
return 0 ;
} ` ,
2025-06-13 06:03:17 +00:00
} ,
] ,
} ,
testcases : {
create : [
{
inputs : {
create : [
{
index : 0 ,
name : "nums1" ,
value : "[1,3]" ,
} ,
{
index : 1 ,
name : "nums2" ,
value : "[2]" ,
2025-03-09 09:45:13 +00:00
} ,
] ,
} ,
2025-06-13 06:03:17 +00:00
expectedOutput : "2.00000" ,
} ,
{
inputs : {
2025-04-09 13:13:26 +00:00
create : [
{
2025-06-13 06:03:17 +00:00
index : 0 ,
name : "nums1" ,
value : "[1,2]" ,
2025-04-09 13:13:26 +00:00
} ,
{
2025-06-13 06:03:17 +00:00
index : 1 ,
name : "nums2" ,
value : "[3,4]" ,
2025-04-09 13:13:26 +00:00
} ,
] ,
} ,
2025-06-13 06:03:17 +00:00
expectedOutput : "2.50000" ,
2025-03-09 09:45:13 +00:00
} ,
] ,
} ,
} ,
2026-05-13 07:10:06 +00:00
{
displayId : 1003 ,
difficulty : "EASY" ,
isPublished : true ,
isTrim : true ,
localizations : {
create : [
{
locale : "en" ,
type : "TITLE" ,
content : "Palindrome Number" ,
} ,
{
locale : "zh" ,
type : "TITLE" ,
content : "回文数" ,
} ,
{
locale : "en" ,
type : "DESCRIPTION" ,
content : ` Given an integer \` x \` , return \` true \` if \` x \` is a palindrome, and \` false \` otherwise.
A palindrome number reads the same backward as forward .
# # Examples
\ ` \` \` shell
Input : x = 121
Output : true
\ ` \` \`
\ ` \` \` shell
Input : x = - 121
Output : false
\ ` \` \`
# # Constraints
\ ` \` \` math
- 2 ^ { 31 } <= x <= 2 ^ { 31 } - 1
\ ` \` \` ` ,
} ,
{
locale : "zh" ,
type : "DESCRIPTION" ,
content : ` 给你一个整数 \` x \` ,如果 \` x \` 是回文整数,返回 \` true \` ;否则返回 \` false \` 。
回 文 数 是 指 正 序 ( 从 左 到 右 ) 和 倒 序 ( 从 右 到 左 ) 读 都 一 样 的 整 数 。
# # 示 例
\ ` \` \` shell
输入 : x = 121
输出 : true
\ ` \` \`
\ ` \` \` shell
输入 : x = - 121
输出 : false
\ ` \` \`
# # 约 束
\ ` \` \` math
- 2 ^ { 31 } <= x <= 2 ^ { 31 } - 1
\ ` \` \` ` ,
} ,
{
locale : "en" ,
type : "SOLUTION" ,
content : ` Reverse half of the digits and compare.
- Negative numbers are never palindromes .
- Numbers ending with 0 are not palindromes unless the number is 0 itself .
- Build a reversed half and compare with the remaining half . ` ,
} ,
{
locale : "zh" ,
type : "SOLUTION" ,
content : ` 可以通过“反转一半数字”来判断。
- 负 数 一 定 不 是 回 文 数 。
- 末 尾 为 0 的 数 不 可 能 是 回 文 ( 除 非 它 本 身 是 0 ) 。
- 逐 步 反 转 后 半 段 , 最 后 与 前 半 段 比 较 即 可 。 ` ,
} ,
] ,
} ,
templates : {
create : [
{
language : "c" ,
content : ` #include <stdbool.h>
# include < stdio.h >
# include < stdlib.h >
bool isPalindrome ( int x ) {
return false ;
}
int main() {
char line [ 256 ] ;
while ( fgets ( line , sizeof ( line ) , stdin ) ) {
int x = atoi ( line ) ;
printf ( "%s\\n" , isPalindrome ( x ) ? "true" : "false" ) ;
}
return 0 ;
} ` ,
} ,
{
language : "cpp" ,
content : ` #include <iostream>
using namespace std ;
class Solution {
public :
bool isPalindrome ( int x ) {
return false ;
}
} ;
int main() {
string line ;
while ( getline ( cin , line ) ) {
int x = stoi ( line ) ;
Solution sol ;
cout << ( sol . isPalindrome ( x ) ? "true" : "false" ) << "\\n" ;
}
return 0 ;
} ` ,
} ,
] ,
} ,
testcases : {
create : [
{
inputs : {
create : [
{
index : 0 ,
name : "x" ,
value : "121" ,
} ,
] ,
} ,
expectedOutput : "true" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "x" ,
value : "-121" ,
} ,
] ,
} ,
expectedOutput : "false" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "x" ,
value : "10" ,
} ,
] ,
} ,
expectedOutput : "false" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "x" ,
value : "0" ,
} ,
] ,
} ,
expectedOutput : "true" ,
} ,
] ,
} ,
} ,
{
displayId : 1004 ,
difficulty : "EASY" ,
isPublished : true ,
isTrim : true ,
localizations : {
create : [
{
locale : "en" ,
type : "TITLE" ,
content : "Valid Parentheses" ,
} ,
{
locale : "zh" ,
type : "TITLE" ,
content : "有效的括号" ,
} ,
{
locale : "en" ,
type : "DESCRIPTION" ,
content : ` Given a string \` s \` containing just the characters \` ()[]{} \` , determine if the input string is valid.
An input string is valid if :
1 . Open brackets are closed by the same type of brackets .
2 . Open brackets are closed in the correct order .
3 . Every close bracket has a corresponding open bracket .
# # Example
\ ` \` \` shell
Input : s = "()[]{}"
Output : true
\ ` \` \` ` ,
} ,
{
locale : "zh" ,
type : "DESCRIPTION" ,
content : ` 给定一个只包括 \` ()[]{} \` 的字符串 \` s \` ,判断字符串是否有效。
有 效 字 符 串 需 满 足 :
1 . 左 括 号 必 须 用 相 同 类 型 的 右 括 号 闭 合 。
2 . 左 括 号 必 须 以 正 确 的 顺 序 闭 合 。
3 . 每 个 右 括 号 都 能 找 到 对 应 的 左 括 号 。
# # 示 例
\ ` \` \` shell
输入 : s = "()[]{}"
输出 : true
\ ` \` \` ` ,
} ,
{
locale : "en" ,
type : "SOLUTION" ,
content : ` Use a stack:
- Push opening brackets .
- On a closing bracket , check whether the top matches .
- At the end , stack must be empty . ` ,
} ,
{
locale : "zh" ,
type : "SOLUTION" ,
content : ` 使用栈来处理:
- 遇 到 左 括 号 入 栈 。
- 遇 到 右 括 号 时 , 检 查 栈 顶 是 否 能 匹 配 。
- 扫 描 结 束 后 栈 为 空 才 是 有 效 字 符 串 。 ` ,
} ,
] ,
} ,
templates : {
create : [
{
language : "c" ,
content : ` #include <stdbool.h>
# include < stdio.h >
# include < string.h >
bool isValid ( char * s ) {
return false ;
}
int main() {
char line [ 4096 ] ;
while ( fgets ( line , sizeof ( line ) , stdin ) ) {
line [ strcspn ( line , "\\n" ) ] = 0 ;
printf ( "%s\\n" , isValid ( line ) ? "true" : "false" ) ;
}
return 0 ;
} ` ,
} ,
{
language : "cpp" ,
content : ` #include <iostream>
# include < string >
using namespace std ;
class Solution {
public :
bool isValid ( string s ) {
return false ;
}
} ;
int main() {
string s ;
while ( getline ( cin , s ) ) {
Solution sol ;
cout << ( sol . isValid ( s ) ? "true" : "false" ) << "\\n" ;
}
return 0 ;
} ` ,
} ,
] ,
} ,
testcases : {
create : [
{
inputs : {
create : [
{
index : 0 ,
name : "s" ,
value : "()" ,
} ,
] ,
} ,
expectedOutput : "true" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "s" ,
value : "()[]{}" ,
} ,
] ,
} ,
expectedOutput : "true" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "s" ,
value : "(]" ,
} ,
] ,
} ,
expectedOutput : "false" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "s" ,
value : "([)]" ,
} ,
] ,
} ,
expectedOutput : "false" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "s" ,
value : "{[]}" ,
} ,
] ,
} ,
expectedOutput : "true" ,
} ,
] ,
} ,
} ,
{
displayId : 1005 ,
difficulty : "EASY" ,
isPublished : true ,
isTrim : true ,
localizations : {
create : [
{
locale : "en" ,
type : "TITLE" ,
content : "Climbing Stairs" ,
} ,
{
locale : "zh" ,
type : "TITLE" ,
content : "爬楼梯" ,
} ,
{
locale : "en" ,
type : "DESCRIPTION" ,
content : ` You are climbing a staircase. It takes \` n \` steps to reach the top.
Each time you can either climb 1 or 2 steps . In how many distinct ways can you climb to the top ?
# # Example
\ ` \` \` shell
Input : n = 3
Output : 3
Explanation : [ 1 + 1 + 1 ] , [ 1 + 2 ] , [ 2 + 1 ]
\ ` \` \`
# # Constraints
\ ` \` \` math
1 <= n <= 45
\ ` \` \` ` ,
} ,
{
locale : "zh" ,
type : "DESCRIPTION" ,
content : ` 假设你正在爬楼梯。需要 \` n \` 阶你才能到达楼顶。
每 次 你 可 以 爬 1 阶 或 2 阶 。 请 问 有 多 少 种 不 同 的 方 法 可 以 爬 到 楼 顶 ?
# # 示 例
\ ` \` \` shell
输入 : n = 3
输出 : 3
解 释 : [ 1 + 1 + 1 ] , [ 1 + 2 ] , [ 2 + 1 ]
\ ` \` \`
# # 约 束
\ ` \` \` math
1 <= n <= 45
\ ` \` \` ` ,
} ,
{
locale : "en" ,
type : "SOLUTION" ,
content : ` This is a classic dynamic programming problem:
- Let \ ` dp[i] \` be the number of ways to reach step \` i \` .
- Transition : \ ` dp[i] = dp[i - 1] + dp[i - 2] \` .
- Space can be optimized to two variables . ` ,
} ,
{
locale : "zh" ,
type : "SOLUTION" ,
content : ` 这是经典的动态规划问题:
- 设 \ ` dp[i] \` 表示到达第 \` i \` 阶的方法数。
- 状 态 转 移 为 \ ` dp[i] = dp[i - 1] + dp[i - 2] \` 。
- 实 现 时 可 以 用 两 个 变 量 将 空 间 优 化 到 \ ` O(1) \` 。 ` ,
} ,
] ,
} ,
templates : {
create : [
{
language : "c" ,
content : ` #include <stdio.h>
# include < stdlib.h >
int climbStairs ( int n ) {
return 0 ;
}
int main() {
char line [ 256 ] ;
while ( fgets ( line , sizeof ( line ) , stdin ) ) {
int n = atoi ( line ) ;
printf ( "%d\\n" , climbStairs ( n ) ) ;
}
return 0 ;
} ` ,
} ,
{
language : "cpp" ,
content : ` #include <iostream>
using namespace std ;
class Solution {
public :
int climbStairs ( int n ) {
return 0 ;
}
} ;
int main() {
string line ;
while ( getline ( cin , line ) ) {
int n = stoi ( line ) ;
Solution sol ;
cout << sol . climbStairs ( n ) << "\\n" ;
}
return 0 ;
} ` ,
} ,
] ,
} ,
testcases : {
create : [
{
inputs : {
create : [
{
index : 0 ,
name : "n" ,
value : "2" ,
} ,
] ,
} ,
expectedOutput : "2" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "n" ,
value : "3" ,
} ,
] ,
} ,
expectedOutput : "3" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "n" ,
value : "5" ,
} ,
] ,
} ,
expectedOutput : "8" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "n" ,
value : "10" ,
} ,
] ,
} ,
expectedOutput : "89" ,
} ,
] ,
} ,
} ,
{
displayId : 1006 ,
difficulty : "MEDIUM" ,
isPublished : true ,
isTrim : true ,
localizations : {
create : [
{
locale : "en" ,
type : "TITLE" ,
content : "Maximum Subarray" ,
} ,
{
locale : "zh" ,
type : "TITLE" ,
content : "最大子数组和" ,
} ,
{
locale : "en" ,
type : "DESCRIPTION" ,
content : ` Given an integer array \` nums \` , find the contiguous subarray (containing at least one number) which has the largest sum, and return its sum.
# # Example
\ ` \` \` shell
Input : nums = [ - 2 , 1 , - 3 , 4 , - 1 , 2 , 1 , - 5 , 4 ]
Output : 6
\ ` \` \` ` ,
} ,
{
locale : "zh" ,
type : "DESCRIPTION" ,
content : ` 给你一个整数数组 \` nums \` ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
# # 示 例
\ ` \` \` shell
输入 : nums = [ - 2 , 1 , - 3 , 4 , - 1 , 2 , 1 , - 5 , 4 ]
输出 : 6
\ ` \` \` ` ,
} ,
{
locale : "en" ,
type : "SOLUTION" ,
content : ` Use Kadane's algorithm:
- \ ` current \` = best subarray sum ending at current index.
- \ ` best \` = global maximum.
- Transition : \ ` current = max(nums[i], current + nums[i]) \` . ` ,
} ,
{
locale : "zh" ,
type : "SOLUTION" ,
content : ` 使用 Kadane 算法:
- \ ` current \` 表示“以当前位置结尾”的最大子数组和。
- \ ` best \` 表示全局最大值。
- 转 移 为 \ ` current = max(nums[i], current + nums[i]) \` 。 ` ,
} ,
] ,
} ,
templates : {
create : [
{
language : "c" ,
content : ` #include <stdio.h>
# include < stdlib.h >
# include < string.h >
int maxSubArray ( int * nums , int numsSize ) {
return 0 ;
}
int * parseIntArray ( char * line , int * len ) {
line [ strcspn ( line , "\\n" ) ] = 0 ;
char * p = line ;
while ( * p && ( * p == '[' || * p == ' ' || * p == ']' ) )
p ++ ;
int capacity = 16 ;
int * arr = malloc ( capacity * sizeof ( int ) ) ;
* len = 0 ;
char * token = strtok ( p , "," ) ;
while ( token ) {
if ( * len >= capacity ) {
capacity *= 2 ;
arr = realloc ( arr , capacity * sizeof ( int ) ) ;
}
arr [ ( * len ) ++ ] = atoi ( token ) ;
token = strtok ( NULL , "," ) ;
}
return arr ;
}
int main() {
char line [ 4096 ] ;
while ( fgets ( line , sizeof ( line ) , stdin ) ) {
int numsSize = 0 ;
int * nums = parseIntArray ( line , & numsSize ) ;
printf ( "%d\\n" , maxSubArray ( nums , numsSize ) ) ;
free ( nums ) ;
}
return 0 ;
} ` ,
} ,
{
language : "cpp" ,
content : ` #include <iostream>
# include < sstream >
# include < string >
# include < vector >
using namespace std ;
class Solution {
public :
int maxSubArray ( vector < int > & nums ) {
return 0 ;
}
} ;
vector < int > parseVector ( const string & line ) {
vector < int > result ;
stringstream ss ( line ) ;
char c ;
int num ;
while ( ss >> c ) {
if ( isdigit ( c ) || c == '-' || c == '+' ) {
ss . putback ( c ) ;
ss >> num ;
result . push_back ( num ) ;
}
}
return result ;
}
int main() {
string line ;
while ( getline ( cin , line ) ) {
vector < int > nums = parseVector ( line ) ;
Solution sol ;
cout << sol . maxSubArray ( nums ) << "\\n" ;
}
return 0 ;
} ` ,
} ,
] ,
} ,
testcases : {
create : [
{
inputs : {
create : [
{
index : 0 ,
name : "nums" ,
value : "[-2,1,-3,4,-1,2,1,-5,4]" ,
} ,
] ,
} ,
expectedOutput : "6" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "nums" ,
value : "[1]" ,
} ,
] ,
} ,
expectedOutput : "1" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "nums" ,
value : "[5,4,-1,7,8]" ,
} ,
] ,
} ,
expectedOutput : "23" ,
} ,
] ,
} ,
} ,
{
displayId : 1007 ,
difficulty : "EASY" ,
isPublished : true ,
isTrim : true ,
localizations : {
create : [
{
locale : "en" ,
type : "TITLE" ,
content : "Binary Search" ,
} ,
{
locale : "zh" ,
type : "TITLE" ,
content : "二分查找" ,
} ,
{
locale : "en" ,
type : "DESCRIPTION" ,
content : ` Given a sorted array of integers \` nums \` and an integer \` target \` , return the index of \` target \` if it exists, otherwise return \` -1 \` .
You must write an algorithm with \ ` O(log n) \` runtime complexity. ` ,
} ,
{
locale : "zh" ,
type : "DESCRIPTION" ,
content : ` 给定一个按升序排列的整数数组 \` nums \` ,和一个目标值 \` target \` 。如果 \` target \` 存在于数组中,返回它的下标;否则返回 \` -1 \` 。
算 法 时 间 复 杂 度 必 须 是 \ ` O(log n) \` 。 ` ,
} ,
{
locale : "en" ,
type : "SOLUTION" ,
content : ` Maintain \` left \` and \` right \` pointers and repeatedly compare \` nums[mid] \` with \` target \` .
Shrink the interval until found or empty . ` ,
} ,
{
locale : "zh" ,
type : "SOLUTION" ,
content : ` 维护 \` left \` 和 \` right \` 两个指针,通过 \` mid \` 与 \` target \` 比较不断缩小区间。
找 到 就 返 回 下 标 , 区 间 为 空 则 返 回 \ ` -1 \` 。 ` ,
} ,
] ,
} ,
templates : {
create : [
{
language : "c" ,
content : ` #include <stdio.h>
# include < stdlib.h >
# include < string.h >
int search ( int * nums , int numsSize , int target ) {
return - 1 ;
}
int * parseIntArray ( char * line , int * len ) {
line [ strcspn ( line , "\\n" ) ] = 0 ;
char * p = line ;
while ( * p && ( * p == '[' || * p == ' ' || * p == ']' ) )
p ++ ;
int capacity = 16 ;
int * arr = malloc ( capacity * sizeof ( int ) ) ;
* len = 0 ;
char * token = strtok ( p , "," ) ;
while ( token ) {
if ( * len >= capacity ) {
capacity *= 2 ;
arr = realloc ( arr , capacity * sizeof ( int ) ) ;
}
arr [ ( * len ) ++ ] = atoi ( token ) ;
token = strtok ( NULL , "," ) ;
}
return arr ;
}
int main() {
char line [ 4096 ] ;
while ( fgets ( line , sizeof ( line ) , stdin ) ) {
int numsSize = 0 ;
int * nums = parseIntArray ( line , & numsSize ) ;
if ( ! fgets ( line , sizeof ( line ) , stdin ) )
break ;
int target = atoi ( line ) ;
printf ( "%d\\n" , search ( nums , numsSize , target ) ) ;
free ( nums ) ;
}
return 0 ;
} ` ,
} ,
{
language : "cpp" ,
content : ` #include <iostream>
# include < sstream >
# include < string >
# include < vector >
using namespace std ;
class Solution {
public :
int search ( vector < int > & nums , int target ) {
return - 1 ;
}
} ;
vector < int > parseVector ( const string & line ) {
vector < int > result ;
stringstream ss ( line ) ;
char c ;
int num ;
while ( ss >> c ) {
if ( isdigit ( c ) || c == '-' || c == '+' ) {
ss . putback ( c ) ;
ss >> num ;
result . push_back ( num ) ;
}
}
return result ;
}
int main() {
string line ;
while ( getline ( cin , line ) ) {
vector < int > nums = parseVector ( line ) ;
if ( ! getline ( cin , line ) )
break ;
int target = stoi ( line ) ;
Solution sol ;
cout << sol . search ( nums , target ) << "\\n" ;
}
return 0 ;
} ` ,
} ,
] ,
} ,
testcases : {
create : [
{
inputs : {
create : [
{
index : 0 ,
name : "nums" ,
value : "[-1,0,3,5,9,12]" ,
} ,
{
index : 1 ,
name : "target" ,
value : "9" ,
} ,
] ,
} ,
expectedOutput : "4" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "nums" ,
value : "[-1,0,3,5,9,12]" ,
} ,
{
index : 1 ,
name : "target" ,
value : "2" ,
} ,
] ,
} ,
expectedOutput : "-1" ,
} ,
] ,
} ,
} ,
{
displayId : 1008 ,
difficulty : "MEDIUM" ,
isPublished : true ,
isTrim : true ,
localizations : {
create : [
{
locale : "en" ,
type : "TITLE" ,
content : "Longest Substring Without Repeating Characters" ,
} ,
{
locale : "zh" ,
type : "TITLE" ,
content : "无重复字符的最长子串" ,
} ,
{
locale : "en" ,
type : "DESCRIPTION" ,
content : ` Given a string \` s \` , find the length of the longest substring without repeating characters.
# # Example
\ ` \` \` shell
Input : s = "abcabcbb"
Output : 3
\ ` \` \` ` ,
} ,
{
locale : "zh" ,
type : "DESCRIPTION" ,
content : ` 给定一个字符串 \` s \` ,请你找出其中不含有重复字符的最长子串的长度。
# # 示 例
\ ` \` \` shell
输入 : s = "abcabcbb"
输出 : 3
\ ` \` \` ` ,
} ,
{
locale : "en" ,
type : "SOLUTION" ,
content : ` Use sliding window:
- Expand right pointer .
- If duplicate appears , move left pointer until valid .
- Keep maximum window length . ` ,
} ,
{
locale : "zh" ,
type : "SOLUTION" ,
content : ` 使用滑动窗口:
- 右 指 针 不 断 扩 展 窗 口 。
- 出 现 重 复 字 符 时 移 动 左 指 针 直 到 窗 口 重 新 合 法 。
- 全 程 维 护 最 大 窗 口 长 度 。 ` ,
} ,
] ,
} ,
templates : {
create : [
{
language : "c" ,
content : ` #include <stdio.h>
# include < string.h >
int lengthOfLongestSubstring ( char * s ) {
return 0 ;
}
int main() {
char line [ 4096 ] ;
while ( fgets ( line , sizeof ( line ) , stdin ) ) {
line [ strcspn ( line , "\\n" ) ] = 0 ;
printf ( "%d\\n" , lengthOfLongestSubstring ( line ) ) ;
}
return 0 ;
} ` ,
} ,
{
language : "cpp" ,
content : ` #include <iostream>
# include < string >
using namespace std ;
class Solution {
public :
int lengthOfLongestSubstring ( string s ) {
return 0 ;
}
} ;
int main() {
string s ;
while ( getline ( cin , s ) ) {
Solution sol ;
cout << sol . lengthOfLongestSubstring ( s ) << "\\n" ;
}
return 0 ;
} ` ,
} ,
] ,
} ,
testcases : {
create : [
{
inputs : {
create : [
{
index : 0 ,
name : "s" ,
value : "abcabcbb" ,
} ,
] ,
} ,
expectedOutput : "3" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "s" ,
value : "bbbbb" ,
} ,
] ,
} ,
expectedOutput : "1" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "s" ,
value : "pwwkew" ,
} ,
] ,
} ,
expectedOutput : "3" ,
} ,
] ,
} ,
} ,
{
displayId : 1009 ,
difficulty : "EASY" ,
isPublished : true ,
isTrim : true ,
localizations : {
create : [
{
locale : "en" ,
type : "TITLE" ,
content : "Best Time to Buy and Sell Stock" ,
} ,
{
locale : "zh" ,
type : "TITLE" ,
content : "买卖股票的最佳时机" ,
} ,
{
locale : "en" ,
type : "DESCRIPTION" ,
content : ` You are given an array \` prices \` where \` prices[i] \` is the price of a given stock on the \` i \` th day.
You want to maximize your profit by choosing a single day to buy one stock and choosing a different day in the future to sell that stock .
Return the maximum profit you can achieve . If no profit is possible , return \ ` 0 \` . ` ,
} ,
{
locale : "zh" ,
type : "DESCRIPTION" ,
content : ` 给定一个数组 \` prices \` ,其中 \` prices[i] \` 表示第 \` i \` 天的股票价格。
你 只 能 选 择 某 一 天 买 入 这 只 股 票 , 并 在 未 来 某 一 天 卖 出 。 请 你 计 算 能 获 得 的 最 大 利 润 。
如 果 无 法 获 得 任 何 利 润 , 返 回 \ ` 0 \` 。 ` ,
} ,
{
locale : "en" ,
type : "SOLUTION" ,
content : ` Track the minimum price seen so far and update the answer with \` price - minPrice \` at each step. ` ,
} ,
{
locale : "zh" ,
type : "SOLUTION" ,
content : ` 遍历数组时维护“历史最低价格”,并用当前价格减去最低价格更新最大利润。 ` ,
} ,
] ,
} ,
templates : {
create : [
{
language : "c" ,
content : ` #include <stdio.h>
# include < stdlib.h >
# include < string.h >
int maxProfit ( int * prices , int pricesSize ) {
return 0 ;
}
int * parseIntArray ( char * line , int * len ) {
line [ strcspn ( line , "\\n" ) ] = 0 ;
char * p = line ;
while ( * p && ( * p == '[' || * p == ' ' || * p == ']' ) )
p ++ ;
int capacity = 16 ;
int * arr = malloc ( capacity * sizeof ( int ) ) ;
* len = 0 ;
char * token = strtok ( p , "," ) ;
while ( token ) {
if ( * len >= capacity ) {
capacity *= 2 ;
arr = realloc ( arr , capacity * sizeof ( int ) ) ;
}
arr [ ( * len ) ++ ] = atoi ( token ) ;
token = strtok ( NULL , "," ) ;
}
return arr ;
}
int main() {
char line [ 4096 ] ;
while ( fgets ( line , sizeof ( line ) , stdin ) ) {
int pricesSize = 0 ;
int * prices = parseIntArray ( line , & pricesSize ) ;
printf ( "%d\\n" , maxProfit ( prices , pricesSize ) ) ;
free ( prices ) ;
}
return 0 ;
} ` ,
} ,
{
language : "cpp" ,
content : ` #include <iostream>
# include < sstream >
# include < string >
# include < vector >
using namespace std ;
class Solution {
public :
int maxProfit ( vector < int > & prices ) {
return 0 ;
}
} ;
vector < int > parseVector ( const string & line ) {
vector < int > result ;
stringstream ss ( line ) ;
char c ;
int num ;
while ( ss >> c ) {
if ( isdigit ( c ) || c == '-' || c == '+' ) {
ss . putback ( c ) ;
ss >> num ;
result . push_back ( num ) ;
}
}
return result ;
}
int main() {
string line ;
while ( getline ( cin , line ) ) {
vector < int > prices = parseVector ( line ) ;
Solution sol ;
cout << sol . maxProfit ( prices ) << "\\n" ;
}
return 0 ;
} ` ,
} ,
] ,
} ,
testcases : {
create : [
{
inputs : {
create : [
{
index : 0 ,
name : "prices" ,
value : "[7,1,5,3,6,4]" ,
} ,
] ,
} ,
expectedOutput : "5" ,
} ,
{
inputs : {
create : [
{
index : 0 ,
name : "prices" ,
value : "[7,6,4,3,1]" ,
} ,
] ,
} ,
expectedOutput : "0" ,
} ,
] ,
} ,
} ,
2025-03-09 09:45:13 +00:00
] ;
export async function main() {
2025-06-13 06:03:17 +00:00
for ( const dockerConfig of dockerConfigData ) {
2026-05-13 07:10:06 +00:00
await prisma . dockerConfig . upsert ( {
where : { language : dockerConfig.language } ,
update : {
image : dockerConfig.image ,
tag : dockerConfig.tag ,
workingDir : dockerConfig.workingDir ,
compileOutputLimit : dockerConfig.compileOutputLimit ,
runOutputLimit : dockerConfig.runOutputLimit ,
} ,
create : dockerConfig ,
2025-06-13 06:03:17 +00:00
} ) ;
}
for ( const languageServerConfig of languageServerConfigData ) {
2026-05-13 07:10:06 +00:00
await prisma . languageServerConfig . upsert ( {
where : { language : languageServerConfig.language } ,
update : {
protocol : languageServerConfig.protocol ,
hostname : languageServerConfig.hostname ,
port : languageServerConfig.port ,
path : languageServerConfig.path ,
} ,
create : languageServerConfig ,
2025-06-13 06:03:17 +00:00
} ) ;
2025-03-16 11:43:21 +00:00
}
2025-06-13 06:03:17 +00:00
for ( const problem of problemData ) {
2026-05-13 07:10:06 +00:00
const existingProblem = await prisma . problem . findUnique ( {
where : { displayId : problem.displayId } ,
select : { id : true } ,
2025-06-13 06:03:17 +00:00
} ) ;
2026-05-13 07:10:06 +00:00
if ( ! existingProblem ) {
await prisma . problem . create ( {
data : problem ,
} ) ;
}
2025-03-09 09:45:13 +00:00
}
2026-05-06 13:16:01 +00:00
// Seed demo users for course/assignment MVP
2026-05-19 08:49:18 +00:00
const teacherPasswordHash = await bcrypt . hash ( "teacher123456#" , 10 ) ;
const studentPasswordHash = await bcrypt . hash ( "student123456#" , 10 ) ;
const adminPasswordHash = await bcrypt . hash ( "admin123456#" , 10 ) ;
const teachers = await Promise . all (
[
"teacher1@example.com" ,
"teacher2@example.com" ,
"teacher3@example.com" ,
] . map ( ( email , index ) = >
2026-05-06 13:16:01 +00:00
prisma . user . upsert ( {
where : { email } ,
update : {
2026-05-19 08:49:18 +00:00
name : ` 课程教师 ${ index + 1 } ` ,
role : "TEACHER" ,
password : teacherPasswordHash ,
2026-05-06 13:16:01 +00:00
} ,
create : {
2026-05-19 08:49:18 +00:00
name : ` 课程教师 ${ index + 1 } ` ,
2026-05-06 13:16:01 +00:00
email ,
2026-05-19 08:49:18 +00:00
role : "TEACHER" ,
password : teacherPasswordHash ,
2026-05-06 13:16:01 +00:00
} ,
} )
)
) ;
2026-05-19 08:49:18 +00:00
const students = await Promise . all (
Array . from ( { length : 9 } , ( _ , index ) = > ` student ${ index + 1 } @example.com ` ) . map (
( email , index ) = >
prisma . user . upsert ( {
where : { email } ,
update : {
name : ` 学生 ${ index + 1 } ` ,
role : "STUDENT" ,
password : studentPasswordHash ,
} ,
create : {
name : ` 学生 ${ index + 1 } ` ,
email ,
role : "STUDENT" ,
password : studentPasswordHash ,
} ,
} )
)
) ;
await prisma . user . upsert ( {
where : { email : "admin@example.com" } ,
update : {
name : "系统管理员" ,
role : "ADMIN" ,
password : adminPasswordHash ,
} ,
create : {
name : "系统管理员" ,
email : "admin@example.com" ,
role : "ADMIN" ,
password : adminPasswordHash ,
} ,
} ) ;
const teacher = teachers [ 0 ] ;
2026-05-06 13:16:01 +00:00
const selectedProblems = await prisma . problem . findMany ( {
orderBy : { displayId : "asc" } ,
take : 2 ,
select : { id : true } ,
} ) ;
if ( selectedProblems . length > 0 ) {
let course = await prisma . course . findFirst ( {
where : {
title : "程序设计基础" ,
teacherId : teacher.id ,
} ,
} ) ;
if ( ! course ) {
course = await prisma . course . create ( {
data : {
title : "程序设计基础" ,
description : "课程作业 MVP 示例课程" ,
teacherId : teacher.id ,
} ,
} ) ;
}
for ( const student of students ) {
await prisma . courseEnrollment . upsert ( {
where : {
courseId_userId : {
courseId : course.id ,
userId : student.id ,
} ,
} ,
update : { } ,
create : {
courseId : course.id ,
userId : student.id ,
role : "STUDENT" ,
} ,
} ) ;
}
const dueAt = new Date ( Date . now ( ) + 7 * 24 * 60 * 60 * 1000 ) ;
let assignment = await prisma . assignment . findFirst ( {
where : {
courseId : course.id ,
title : "第一次编程作业" ,
} ,
select : { id : true } ,
} ) ;
if ( ! assignment ) {
assignment = await prisma . assignment . create ( {
data : {
courseId : course.id ,
title : "第一次编程作业" ,
description : "完成基础题目,熟悉在线评测流程" ,
dueAt ,
published : true ,
createdById : teacher.id ,
} ,
select : { id : true } ,
} ) ;
} else {
await prisma . assignment . update ( {
where : { id : assignment.id } ,
data : {
dueAt ,
published : true ,
description : "完成基础题目,熟悉在线评测流程" ,
} ,
} ) ;
}
await prisma . assignmentProblem . deleteMany ( {
where : { assignmentId : assignment.id } ,
} ) ;
await prisma . assignmentProblem . createMany ( {
data : selectedProblems.map ( ( problem , index ) = > ( {
assignmentId : assignment.id ,
problemId : problem.id ,
maxPoints : 100 ,
order : index + 1 ,
} ) ) ,
skipDuplicates : true ,
} ) ;
}
2025-03-09 09:45:13 +00:00
}
main ( ) ;